2019/8 Webアーキテクチャ基礎(前編)

今回は、Web開発する上で基本的なアーキテクチャ概念を紹介します。※本記事はWeb Architecture 101を意訳したものです。Thank you Jonathan Fulton.
元の記事が長いので前編・後編に分けました。
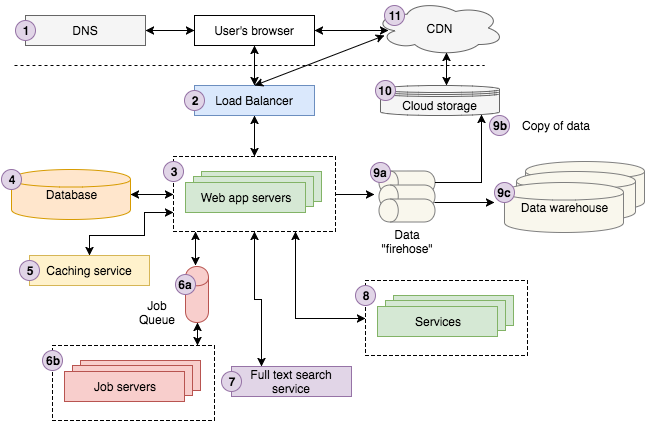
上の図は、私達のWebサービスStoryblocksのアーキテクチャー図です。 Web開発の経験がない人には複雑だと思うかもしれません。 各コンポーネントについて説明する前に、わかりやすくなるよう以下ユースケースを紹介します。
ユーザがGoogleで「森の強くて美しい霧と光」について検索します。最初の結果はStroyblocksの一流のフォトストックとサイトからです。ユーザは詳細ページを見るためにその結果をクリックします。するとブラウザは、まずDNSサーバにリクエストを送信してStoryblocksへのコンタクト方法を探し、見つけた方法でStoryblocksへリクエストを送信します。
送信したリクエストはStoryblocksのロードバランサーにヒットし、リクエストを処理するためにその時点で稼働している10台ぐらいのWebサーバの中からランダムに選択します。Webサーバはキャッシュサービスから画像データを探し、残りのデータをDBから取得します。画像のカラープロファイルがまだ計算されていないので、「カラープロファイル」ジョブをジョブキューに送信します。ジョブキューは非同期で処理し、結果をDBに更新します。
次に、全文検索サービスにリクエストを送信し、写真のタイトルから類似の写真を探します。ユーザがStoryblocksにログインしている場合は、アカウントデータからユーザのアカウント情報を調べます。最後にクラウドストレージに記録し、その後データウェアハウスに読み込まれるようページ閲覧イベントを発生させます。アナリストはこの情報を利用してビジネスに関する問題に役立てます。
そしてWebアプリサーバはHTMLを書き出し、HTMLデータを最初に通ったロードバランサを介してレンスポンスとしてユーザのブラウザへ返します。このHTMLページは、CDNにつながっているクラウドストレージ上のJavascriptやCSSを含んでいるため、ブラウザはCDNにアクセスしてコンテンツを取得します。その後、ブラウザはユーザが見えるようページを描画します。
次に、各コンポーネントを順を追って説明します。各コンポーネントの基本的な紹介では、Webアーキテクチャを通じて優れたメンタルモデルを紹介します。また、Storyblocksで私が学んだことに基づいた具体的なおすすめの実装に関する記事もフォローアップします。
1. DNS
DNSは「Domain Name System」の略で、World Wide Webのための根幹となる技術です。基本的にDNSはドメイン名(例:google.com)からIPアドレス(例:85.129.83.120)へのキーバリュー形式での検索機能を提供します。これはコンピュータが適切なIPアドレスのサーバへリクエストを送るために必要です。電話番号に例えると、ドメイン名は「山田太郎」でIPアドレスは「090-1234-5678」と言えるでしょう。山田太郎の電話番号を調べるにはアドレス帳が必要なように、ドメインからIPアドレスを調べるにはDNSが必要です。つまりDNSはインターネット用のアドレス帳と言えるでしょう。
詳細については入門レベルとしては重要ではないので、ここでは説明を省略します。
2. ロードバランサー
ロードバランサーの詳細に入る前に、水平方向と水色方向のアプリケーションスケールについて話す必要があります。水平スケールと垂直スケールの違いは何でしょう?とてもシンプルな記事がStackOverflowにありますが、水平スケールはサーバを追加し増やすことでスケールすることです。一方、垂直スケールはすでにあるサーバに対してCPUを強化したりメモリを増やすことを意味します。
シンプルな構成を保ち、壊れるときは壊れても良いように、Web開発においては常に(ほぼ)水平スケールにしたくなります。サーバはまれに壊れます。ネットワークは劣化します。データセンター全体も時々接続できなくなることがあります。複数台のサーバを持つことで計画的に一部だけ停止しつつ、アプリ全体としては継続して動作させることができフォールトレランス性が向上します。2つ目に、水平スケールではバックエンドの様々な部分(Webサーバ、DBサーバ、サーバXXX等々)をそれぞれ別のサーバにすることで疎結合にすることができます。最後に、垂直スケールではスケールに限界があります。1台でどんなアプリケーションでも十分処理できるようなコンピュータは世の中にありません。これは小さい会社にも当てはまりますが、Googleの検索機能は典型的な例だと思ってください。例えばStoryblocksは150~400のAWS EC2インスタンスが起動しています。垂直スケールですべての計算を賄うことは難しいでしょう。
それではロードバランサーに戻ります。ロードバランサーは水平スケールするために必要なものです。ロードバランサーはリクエストを一般的にクローンまたはミラーリングされた複数台のサーバに流し、サーバからのレスポンスをブラウザに返します。どのサーバも同じようにリクエストを処理することで、ロードバランサーはリクエストを複数台のサーバに分散させるだけで過負荷にならないようにできます。
これだけです。概念的にロードバランサーは単純明快です。内部で行われている処理的には複雑ですが、基礎レベルでは飛び込む必要はありません。
3. Webアプリサーバ
高いレベルのWebアプリサーバは比較的簡単に説明できます。ユーザのリクエストを受け取り、ブラウザにHTMLを返すようなビジネスロジックを実行します。この処理を行うために、WebアプリサーバはDB、キャッシュレイヤ、ジョブキュー、検索サービス、他のマイクロサービス、データ/ロギングキューなど様々なバックエンドと通信します。前述のように、リクエストを処理するためにロードバランサーに接続されているWebアプリサーバは少なくとも2つ、多くの場合はそれ以上起動させています。
Webアプリサーバの実装には特定の言語(Node.js、Ruby、PHP、Scala、Java、C#.NETなど)とその言語用のWeb MVCフレームワーク(Express for Node.js, Ruby on Rails, Play for Scala, Laravel for PHPなど)を選ぶ必要があることを知っておきましょう。ただし、これらの言語とフレームワークの詳細については、この記事の範囲を超えるので紹介しません。
4. DBサーバ
最近のWebアプリサーバは1つ以上のDBを利用して情報を保存しています。DBはデータ構造の定義、新しいデータの挿入、既存データの検索、既存データの更新または削除、データ全体にわたる処理などを提供します。ほどんどの場合、Webアプリサーバはジョブサーバ同様に直接Webアプリサーバと通信します。さらに、各バックエンドサービスは他のサーバから分離された別のDBサーバを持つことができます。
各アーキテクチャについて特定のテクノロジに関する詳細な説明はしません。SQLとNoSQLについて言及することも害を与えかねないでしょう。
SQLは「Structured Query Language」の略で、1970年代に発明され、リレーショナルデータセットを照会するための標準的な方法を提供してくれました。SQLデータベースは共通ID(通常は整数)を介してリンクされているテーブルにデータを格納します。それでは、ユーザの住所履歴情報を保存する簡単な例をみてみましょう。2つのテーブルusersとuser_addressesがあり、それらはユーザIDによってリンクされています。単純化した内容については下の画像を参照してください。user_addressesのuser_id列はusersテーブルのid列への「外部キー」としてリンクされています。
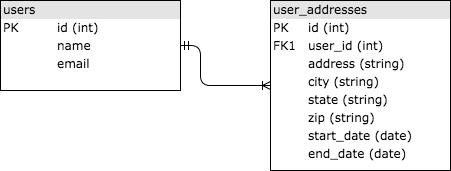
SQLについてあまりよく知らないのであれば、ここのKhan Academyにあるようなチュートリアルをやってみることを強くおすすめします。SQLはWeb開発のいたるところに存在するので、少なくともWebアプリを適切に設計するために基本事項を知るとよいでしょう。
NoSQLは「Non-SQL」の略で、大規模Webアプリによって生成される大量のデータを処理するために現れた新しいデータベース技術です。(SQLのほとんどは水平方向にはあまりスケールできず、限界のある垂直方向にしかスケールできません。)NoSQLについて何も知らないなら、これらのようないくつかのハイレベルな紹介から始めることをおすすめします。
- https://www.w3resource.com/mongodb/nosql.php
- http://www.kdnuggets.com/2016/07/seven-steps-understanding-nosql-databases.html
- https://resources.mongodb.com/getting-started-with-mongodb/back-to-basics-1-introduction-to-nosql
また一般的にNoSQLデータベースのインターフェースとしてもSQLを使用しているため、SQLを知らない場合は習得する必要があります。それを回避する方法はほとんどありません。
5. キャッシュサービス
キャッシュサービスはO(1)計算量でデータを保存・検索できるシンプルなキー/バリューデータストアを提供します。アプリは通常キャッシュサービスを利用して高コストな計算結果を保存し、データが必要になったとき再計算するのではなくキャッシュから結果を取得します。アプリはDBクエリ、外部サービス、特定URLのHTML等々をキャッシュする場合があります。以下に実際のアプリの例を示します。
- Googleは「犬」や「テイラースイフト」など一般的な検索結果を毎回計算するのではなくキャッシュします
- Facebookはログイン時に表示されるデータ(投稿記事、友人など)の多くをキャッシュしています。Facebookのキャッシュ技術に関する詳細な記事はこちらをご覧ください
- StoryblocksはReactのサーバサイドレンダリング結果、検索結果、先行入力結果などのHTML出力をキャッシュします
広く普及している2つのキャッシュサーバ技術はRedisとMemcacheです。詳細については別の投稿で説明します。
前編は以上です。次回、後編でジョブキュー&サーバ以降について紹介します。